Donald Trump isn’t “there yet” in supporting Republican Speaker of the House Paul Ryan. Ryan has repeatedly chastised Trump and famously said he wasn’t there yet on Trump earlier this year. How strong is his distaste? Did he (and his writers) overcome it at the RNC Convention?
Let’s examine this question by looking at how people refer to other people (I’ll be using the term ‘referents’ and building on my previous post about the most DNC-y and RNC-y words).

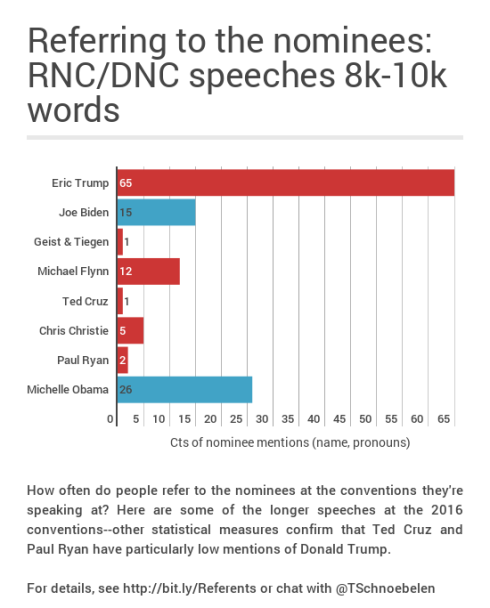
What children and spouses do and don’t do
If Paul Ryan showed distaste for Trump in his choice of referents, then we might expect that they will be pretty different than how someone who loves/likes someone behaves. Families have all sorts of interesting dynamics, but let’s begin by assuming that spouses and children speaking at a major convention will perform love. So let’s start with them. I’ve described all the referents in sections below, but they can be summarized this way:
- Children don’t refer to their parents by their first name or their last name only
- Spouses don’t refer to their partners by last name only (but obviously first name only is fine)
- Full names are available for children (and spouses) to use for rhetorical effect
- Basically all your pronouns refer to the nominee who is your relative
- You don’t refer to the other candidate at all
What does the average DNC/RNC person do with first/last names?
Let’s look at the RNC/DNC speeches that aren’t given by family members (or the nominees).
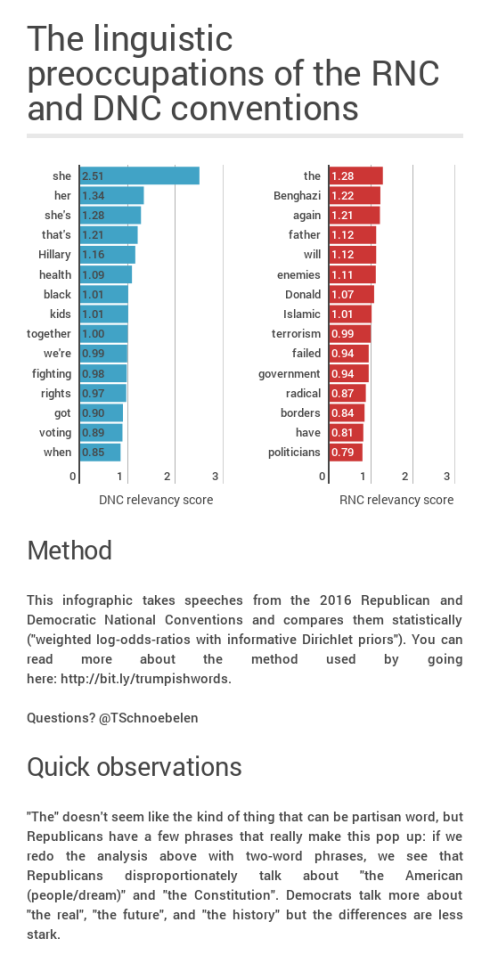
Across 51 RNC speeches, there are 160 Donald Trump‘s, 4 Donald J. Trump‘s. There are 4 Mr. Trump‘s, 1 Fred Trump, 2 President Trump‘s; there are 22 other Trump uses and 30 other Donald’s. Across 42 non-Clinton DNC speeches, there are 145 Hillary Clinton‘s, 10 other Clinton‘s, and 130 other Hillary‘s. In other words…there’s a lot more naming of Hillary Clinton at the DNC.
There are six RNC speakers who don’t use Donald or Trump at all: Cotton, Ernst, Kirk, Mukasey, Perry, and Sullivan. Across 42 DNC speakers, only one of them doesn’t use Hillary or Clinton: Kareem Abdul-Jabbar. In a moment, we’ll tackle whether counts of names are a good measure. Before I do that, let me propose something slightly more complicated than simple counts.
How could we measure naming preferences?
Different speakers have different areas of focus and they have different word counts, so at a minimum we should take those into consideration. We’re on pretty firm footing, it would seem, to say that the convention at a convention is to mention the nominee. So the longer a speech goes without saying their name, the odder it is.
I’m interested in whether tf-idf can be used to quantify this oddness. Normally, tf-idf (“term frequency-inverse document frequency) is used for things like search retrieval–if you’re searching for a term across a bunch of documents, tf-idf is one way to figure out you should show Document X but not Document Y. It’s also a way of quantifying “aboutness”.
Across the RNC speakers who aren’t Trumps, the average tf-idf of Donald is 0.055 (median 0.045). The average for Trump is 0.052 (median 0.051). The average tf-idf at the DNC for Hillary is 0.077 (median 0.071), the average tf-idf there for Clinton is 0.042 (median 0.037).
Sniff test #1: Do the biggest scores pick out big supporters?
Let’s look at how has a high tf-idf score for the nominee names:
- Hillary
- Alison Lundergan Grimes (0.20 tf-idf; 8 Hillary‘s, 2 Hillary Clinton‘s, 1 President Clinton (Bill, not counted here))
- Gabby Giffords (0.16 tf-idf; 3 Hillary‘s)
- Ryan Moore (0.15 tf-idf; 6 Hillary‘s, 2 Hillary Clinton‘s)
- Donald
- Dana White (0.20 tf-idf; 5 Donald Trump‘s, 4 Donald‘s)
- Rick Scott (0.14 tf-idf; 5 Donald Trump‘s, 1 Donald)
- Laura Ingraham (0.13 tf-idf; 6 Donald Trump‘s)
- Clinton
- Joe Sweeney (0.11 tf-idf; 2 Hillary Clinton‘s, 2 Secretary Clinton‘s, 1 Hillary)
- Tom Harkin (0.11 tf-idf; 6 Hillary Clinton‘s)
- O’Malley (0.11 tf-idf; 7 Hillary Clinton‘s)
- Trump
- Kerry Woolard (0.14 tf-idf; 5 Donald Trump‘s, 3 the Trumps (about the family, not counted here), 2 Trump Winery (counted))
- Laura Ingraham (0.13 tf-idf for this term, too, see above)
- Harold Hamm (0.13 tf-idf; 4 Donald Trump‘s, 2 President Trump‘s)
If tf-idf of the nominees names is important, than these people should be among the biggest proponents. Is that true?
Well, Alison Lundergan Grimes is described as a “close family friend“. Gabby Giffords had a very short speech since it’s hard for her to speak but she has endorsed Clinton since January 10th. Ryan Moore met Hillary Clinton when he was seven years old.
The people who have high tf-idf scores for Clinton are less clear to me. Retired Iowa Senator Tom Harkin endorsed Hillary Clinton in August of 2015, which is an early endorsement. But Martin O’Malley ran against Clinton and hasn’t always had nice things to say, but he includes her passionately from start to end. Finally, I’m not quite as sure what to do with NYPD detective Joe Sweeney–is he an ardent, long-term Clinton supporter? That’s a real question. But in the meantime, every mention of the Democratic nominee in his speech is glowing.
Trump has been good to president of the UFC, Dana White over the years. Rick Scott only endorsed Trump after he had already won the Florida primaries, though in the speech he goes out of his way to say Trump is a friend.
Laura Ingraham has supported Trump in various ways for a while and her speech seems pretty full bodied. Kerry Woolard is the General Manager of Trump Winery, so whatever she feels, she has a big incentive to perform support. Harold Hamm is a potential cabinet pick for Trump and very pro-Trump.
Not surprisingly, mentions of the first name alone suggest familiarity. There are various ways we might discount or weight the tf-idf scores for first name vs. last name vs. full name. But for now, the top tf-idf ones do seem to be performing strong support.
Sniff test #2: What about no-naming?
Kareem Abdul-Jabbar never mentions the Democratic nominee in his prepared remarks. Instead, he focuses on Donald Trump and Mike Pence as being deeply problematic because of their penchants for discrimination. I’m not sure what Abdul-Jabbar’s beliefs are, of course, but it does seem plain that in his speech he is more anti-Trump than particularly pro-Clinton. The words with the highest tf-idf scores for him are Jefferson, Khan, tyranny, and discrimination.
The RNC has a lot more no-namers. And they have longer (more problematic) histories with Trump.
- Joni Ernst’s highest tf-idf words include Iowa, my, our, country, and failed
- Tom Cotton’s highest tf-idf words include wishes, infantryman, Army, punishing, volunteered, and peace
- Charlie Kirk’s highest tf-idf words include campuses, democrats, party, and youngest
- Michael Mukasey’s highest tf-idf words include falsely, she, emails, law, and hacked
- Rick Perry’s highest tf-idf words include battles, Texas, and veterans
- Dan Sullivan’s highest tf-idf words include Senate, we, and United States
Do these people dislike Trump? I like this headline: “Rick Perry Gives Speech At Trump-Centered Convention, Pretends Donald Trump Doesn’t Exist“. Ernst declined to be considered for Vice President and has tended to avoid talking about Trump or not said great things about him. Tom Cotton has spoken out against Trump’s Muslim ban. Sullivan, like most of the Alaska delegation, was more about supporting the nominee than Trump specifically.
Finally, in May of this year, Charlie Kirk posted an article called “I saw Trump coming, and I chose to ignore it”. I can’t tell you what’s in that article, though, because he’s removed it. But that’s the syntax of a critic not a supporter.
In other words, failure to mention the nominee’s name, minimally means the speaker is concentrating on something other than the nominee. I think it also is reasonable to say that people who don’t really support the nominee much will avoid mentioning them.
What does Paul Ryan do?
Paul Ryan refers to Donald Trump as Donald Trump two times at the RNC convention:
-
In the opening of his speech: “But you’ll find me right there on the rostrum with Vice President Mike Pence and President Donald Trump.”
- And in the middle: “Only with Donald Trump and Mike Pence do we have a chance at a better way.”
(Ponder-point: how important is it that Donald Trump’s mentions link him to Mike Pence, the “stable” one?)
This is basically even with the amount Ryan mentions the rival nominee. He says Hillary Clinton once, Hillary twice and Clinton twice (“another Clinton”, “The Clinton years”).
Ryan has zero pronouns referring to either Trump or Clinton.
Is this surprising? Ryan’s speech has 1,609 words, making it the tenth longest at the RNC this year (in order: Trump, Pence, Barrack, Ivanka, Gingrich, Geist and Tiegen, Cruz, Christie, Eric, then Ryan).
Only a few people have tf-idf scores for Donald that are lower than Ryan’s: the six people who never use his name at all as well as the duo of Mark Geist/John Tiegen and…Ted Cruz.
There are seven people who don’t use Trump at all (the six above plus Jason Beardsley). Again, only Geist/Tiegen and Ted Cruz have lower tf-idf scores. Geist and Tiegen just say Donald Trump once and Ted Cruz also just says it once:
-
Geist & Tiegen: Someone who will have our backs. Someone who will bring our guys home. Someone who will lead with strength and integrity. That someone is Donald Trump.
-
Ted Cruz: I want to congratulate Donald Trump on winning the nomination last night.
The Geist & Tiegen mention doesn’t really look like a snub so much as they are talking about other stuff (their highest tf-idf words include Glen, arm, and Tripoli…they also have 4 rhetorical uses of someone that are really referring to Trump).
The Ted Cruz mention is…well, if you’re reading this you probably already have read about his non-endorsement and know he’s a very Big Anti-fan of Trump. And Paul Ryan’s statistics are very close to his.
You’re going to tell me about Bernie, right?
Sure, okay. Bernie’s speech at the DNC has 14 uses of Hillary Clinton and one Secretary Clinton. That means that Bernie’s tf-idf scores for Hillary are in the top quartile in the DNC and the tf-idf scores for Clinton are just under the median for the DNC speakers.
He’s largely seen as giving a complete and total endorsement of Clinton in his speech, so these numbers check out.
Hey, I want the gory details about the family members
Chelsea, Ivanka, and Eric
If you’re Chelsea, you don’t call your mom, “Hillary” or “Clinton” or “Hillary Clinton”. It’d be a bit weird, right? All of her uses of pronouns refer to her mom.
- The pronoun she is fine (31 uses)
- So is her (16 uses)
- 9 my mom
- 1 my own mother, 1 My wonderful, thoughtful, hilarious mother, 1 a mother (about Hillary) and 5 my mother
Chelsea’s two uses of he are about her son Aidan–there’s no mention of Trump in her introduction of her mom.
Ivanka does something different. Like Chelsea, she never refers to her parent by just his first name or just his last name. But for rhetorical effect, she does refer to Donald Trump seven times and Donald J. Trump once. (If you want to track everything: Ivanka refers to Trump Tower twice and Trump Organization once.) Like Chelsea, all of Ivanka’s pronoun uses are about her parent-the-nominee:
- Ivanka has 37 uses of he
- She has 27 uses of his
- And she has 12 uses of him
- 18 my father‘s
Ivanka’s 1 her (re: America) and 1 she (re: a woman becoming a mother).
Eric uses Trump twice–once in reference to The Eric Trump Foundation and once to say he has never “been more proud to be a Trump”. All but one of Eric’s pronouns refer to his dad:
- Eric has 25 uses of he
- 18 his
- 1 him
- 1 my dad and 1 Dad
- 19 my father’s
The only one instance that doesn’t refer to his dad is also the only time he uses a female pronoun: “the veteran tuning into this speech from his or her hospital bed”.
Bill and Melania
Spouses have different rights and requirements. Bill Clinton does refer to his wife as Hillary (25 times).
- She (134 times in that form, 9 she’s, 3 she’ll and 1 she’d)
- Her (67 times and 2 hers)
- (No uses of wife)
He also has one use of their shared last name: “after Hillary testified before the education committee and the chairman, a plainspoken farmer, said looks to me like we elected the wrong Clinton”.
Bill Clinton never refers to Trump by name or by pronoun. Bill Clinton’s he‘s are about Gingrich (1), Obama (2), Don Jones (3), an imaginary son for checking on a racist school (1), Franklin Garcia (1), a Law School classmate (1). His him‘s are about a segregationist (1), DeLay (1), Rangel (1). The three his in Bill Clinton’s speech are about Obama (2) and Don Jones (1).
Like Ivanka, Melania refers to Donald Trump by his full name several times. She uses Donald J. Trump twice and Donald Trump once. She refers to the Trump family and a Trump contest (that refers to the campaign to November). She refers to Donald 14 other times. All her pronouns are about him (Melania doesn’t use any female pronouns in her speech):
- 19 he
- 12 his
- 4 him
- 6 my husband‘s
I guess I should wrap up with a note here to reaffirm that speakers have lots of help writing their speeches. That makes it a bit more likely that they will fit certain conventions (e.g., to make a good First Lady speech, copy from a former First Lady speech). This post has been about getting a handle on those hidden rules and seeing how far people deviate from them. We don’t have access to people’s hearts–but we do have access to what they write and say and can compare it to others.